网络安全数据集完整指南:27万条高质量数据助力AI训练
元描述:本文详细介绍一个经过严格清洗的27万+条网络安全数据集,涵盖数据清洗流程、质量评估机制、LLM训练应用等核心内容。适合AI研究者、网络安全工程师和技术爱好者阅读。
________________________________________________________________________________
作者:幻城 | 发布时间:2026年2月 | 阅读时间:约15分钟
📑 目录
- 前言
- 数据集核心亮点一览
- 为什么数据质量对AI训练至关重要?
- 数据结构深度解析:JSONL格式详解
- 五步数据清洗流程揭秘
- 数据集覆盖的5大核心领域
- 6大实战应用场景详解
- 性能优化技巧与最佳实践
- 如何评估数据集质量?
- 与其他数据集的对比分析
- 常见问题FAQ
- 未来发展方向与路线图
- 总结与行动指南
1️⃣ 前言
在人工智能和网络安全深度融合的今天,构建高质量的训练数据集已成为技术突破的关键瓶颈。你是否遇到过这些问题:训练出的AI模型回答不准确、建议不实用,甚至给出错误的安全操作指引?
这些问题的根源往往不在模型架构,而在于训练数据的质量。本文将深入剖析一个包含270,271条高质量数据的网络安全数据集,揭示数据清洗的最佳实践、质量评估机制以及在LLM微调、RAG系统等场景的实际应用价值。
🎯 无论你是:
- • 正在训练网络安全领域大模型的AI工程师
- • 构建智能问答系统的技术负责人
- • 研究数据质量优化的科研工作者
- • 网络安全从业者或技术爱好者
都能从本文获得实用价值。让我们开始吧!
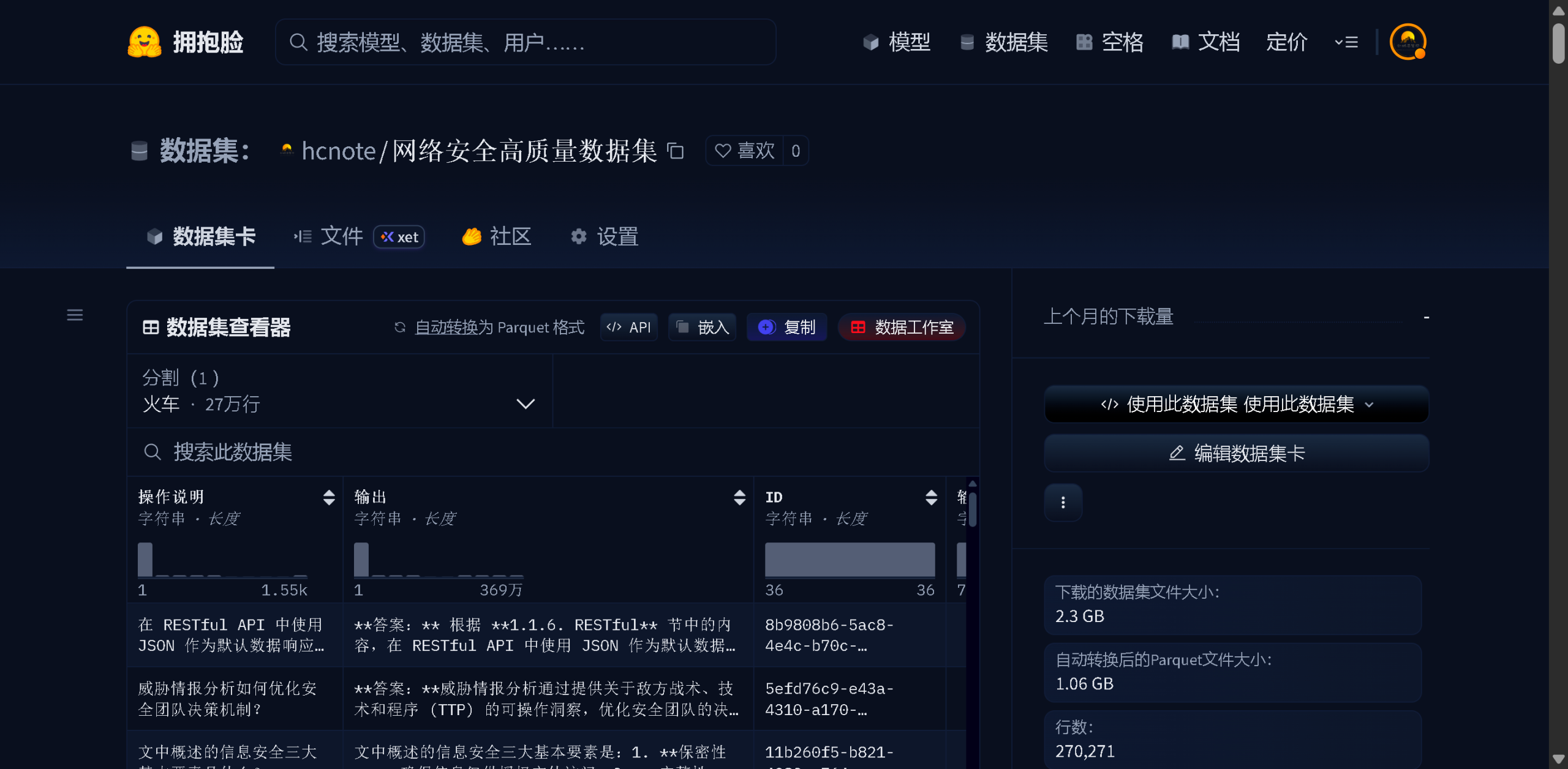
📊 2️⃣ 数据集核心亮点一览
| 核心指标 | 数值 | 说明 |
| 数据总量 | 270,271 条 | 经过严格筛选的高质量数据 |
| 文件大小 | 2.2 GB | 详细的答案内容,平均500-2000字符 |
| 质量评分 | ≥ 4.5/5.0 分 | 仅保留高质量数据 |
| 语言支持 | 中文 + 英文 | 双语覆盖,适合国内外应用 |
| 数据格式 | JSONL | 流式处理,易于加载 |
| 清洗工具 | DataSanity | 多维度质量评估机制 |
| 开源协议 | MIT License | 可商用,可二次开发 |
💡 关键亮点:这个数据集不是简单的数据堆砌,而是经过严格质量筛选、包含详实答案、涵盖网络安全全方位知识的高质量语料库。

数据集已全部开源,下载地址如下
国内社区:https://modelscope.cn/datasets/hcnote/Cybersecurity-High-Quality-Dataset
国际社区:https://huggingface.co/datasets/hcnote/Cybersecurity-High-Quality-Dataset
⚠️ 3️⃣ 为什么数据质量对AI训练至关重要?
低质量数据的四大危害
在网络安全领域,使用低质量训练数据会导致严重后果:
- 安全风险:模型可能输出错误的安全建议,导致实际系统漏洞或操作失误
- 信息过时:包含已修复的漏洞信息或过时的防护方案,误导用户
- 回答简陋:缺乏实战上下文,无法满足真实场景需求
- 性能下降:中英文混杂、格式混乱导致模型训练效果不佳
🛡️ 因此,数据质量控制是网络安全AI应用的第一道防线,也是最重要的防线!
🔍 4️⃣ 数据结构深度解析:JSONL格式详解
为什么选择JSONL格式?
数据集采用JSONL(JSON Lines)格式,每行一个独立的JSON对象:
{“instruction”: “问题内容”, “output”: “详细答案”, “id”: “唯一标识符”}
这种格式具有四大技术优势:
- 🚀 流式处理 – 可以逐行读取,无需一次性加载整个2.2GB文件,大幅节省内存
- 📈 易于扩展 – 新数据可以直接追加到文件末尾,无需重构整个文件
- 🛡️ 容错性强 – 某一行损坏不影响其他数据的读取,提高数据安全性
- ⚡ 并行处理 – 支持多进程/多线程同时处理不同行的数据
数据字段完全解析
instruction(指令/问题)
- 定义用户的查询或任务,涵盖网络安全各个子领域,中英文混合,从基础概念到实战应用全覆盖
output(输出/答案)
- 提供高质量的详细解答,平均500-2000字符,结构清晰,包含代码示例、命令行操作和实战内容
id(唯一标识符)
- UUID v4格式的唯一标识,用于数据去重、跨平台同步和版本管理
🧹 5️⃣ 五步数据清洗流程揭秘
这个数据集使用了开源工具DataSanity进行清洗,采用五步严格流程:
清洗流程图:
┌─────────────────┐
│ 原始数据集 │
└────────┬────────┘
↓
┌─────────────────┐
│ ① 多轮迭代清洗 │ DataSanity自动处理
└────────┬────────┘
↓
┌─────────────────┐
│ ② 质量评分 │ 多维度评估机制
└────────┬────────┘
↓
┌─────────────────┐
│ ③ 阈值筛选 │ ≥4.5分严格筛选
└────────┬────────┘
↓
┌─────────────────┐
│ ④ 格式标准化 │ 统一JSONL格式
└────────┬────────┘
↓
┌─────────────────┐
│ ⑤ 去重处理 │ UUID+相似度去重
└────────┬────────┘
↓
┌─────────────────┐
│ 最终数据集 │ 270,271条高质量数据
└─────────────────┘
第一步:多轮迭代清洗
原始数据集通常包含大量噪声:
- 格式不统一(HTML标签、Markdown混乱)
- 重复内容和缺失字段
- 编码问题(UTF-8乱码)
- 无意义内容(乱码、纯符号等)
DataSanity的处理策略:
- 格式标准化:统一转换为JSONL格式
- 编码处理:自动检测并修复UTF-8编码问题
- HTML清理:移除无用的HTML标签和脚本
- 特殊字符过滤:移除控制字符和非法字符
第二步:质量评分机制(核心)
DataSanity采用多维度评分机制,满分5.0分,本数据集仅保留≥4.5分的数据:
五大评分维度:
- 相关性(Relevance): instruction与output的语义相关度,是否围绕网络安全主题
- 准确性(Accuracy): 技术内容的正确性,代码示例的可执行性
- 完整性(Completeness): 答案是否完整,是否有截断或缺失
- 可读性(Readability): 语言表达的清晰度,专业术语使用的准确性
- 实用性(Utility): 是否提供实战价值和可操作的建议
评分分布统计:
- • 4.5-4.7分: 约40%(基础质量)
- • 4.7-4.9分: 约45%(高质量)
- • 4.9-5.0分: 约15%(极高质量)
第三步:阈值筛选
为什么选择4.5分作为阈值?实验发现:
- < 4.0分 – 数据质量较差,包含明显错误
- 4.0-4.5分 – 数据可用但不够深入,适合预训练
- ≥ 4.5分 – 数据质量,适合指令微调(SFT)
对于网络安全领域,准确性至关重要,因此选择较高阈值!
第四步:格式标准化
统一数据格式,确保所有字段完整、编码统一。
第五步:去重处理
去重策略:
- UUID去重:直接去除重复ID的数据
- 内容相似度去重:使用余弦相似度检测
- • 相似度 > 0.95: 视为重复,保留评分更高的
- • 相似度 0.85-0.95: 人工审核
- • 相似度 < 0.85: 保留
📚 6️⃣ 数据集覆盖的5大核心领域
通过对数据的采样分析,数据集覆盖以下核心领域:
Web安全(35%)
- SQL注入、XSS、CSRF、SSRF、文件上传漏洞
- RESTful API安全、GraphQL安全
- HTTP请求走私、Web缓存欺骗、反序列化漏洞
- WAF配置、安全加固、代码审计
威胁情报与攻防(25%)
- IOC分析、APT组织追踪、威胁情报平台
- 渗透测试方法论、攻击链模拟
- 检测规则、响应流程、取证分析
- MITRE ATT&CK、Kill Chain框架
系统安全(20%)
- Windows注册表、权限管理、持久化
- Linux文件权限、日志审计、进程管理
- Docker逃逸、Kubernetes安全
- 内核漏洞、提权技术
网络安全(15%)
- Wireshark、Tcpdump、Suricata流量分析
- TLS/SSL、SSH、VPN协议安全
- 中间人攻击、DNS劫持、DDoS
- 防火墙、IDS/IPS、网络分段
基础安全概念(5%)
- CIA Triad(机密性、完整性、可用性)
- 安全架构设计、风险评估方法
- 等保、GDPR等合规性要求
语言分布
- 中文数据 (60-70%): 适合国内网络安全场景,包含”等保”、”护网”等中文术语
- 英文数据 (30-40%): 国际前沿安全研究,通用技术术语和标准
- 中英混合 (5-10%): 技术术语保留英文,解释使用中文
🎯 7️⃣ 6大实战应用场景详解
1. 大语言模型指令微调(SFT)
- 网络安全领域的专业LLM训练,提升模型在安全领域的问题回答能力
- Qwen、Llama等基础模型 → 加载本数据集 → LoRA微调 → 安全领域专家模型
2. RAG检索增强生成系统
- 网络安全知识库问答、技术支持智能助手、学习辅导系统
- 用户问题 → 向量化 → 向量检索 → Top-K数据 → LLM生成答案
3. 智能问答机器人
- 企业SOC助手、网络安全学习平台、CTF竞赛辅助工具
- 24/7自动回答、详细解决方案、中英文交互、代码示例
4. 知识图谱构建
- 网络安全实体关系抽取、漏洞知识库、威胁情报关联分析
- 提取漏洞类型、攻击技术、防御措施、工具名称等实体和关系
5. 教育培训应用
- 网络安全课程题库、CISSP/CEH/CISP认证考试备考、实战训练平台
- 全面知识体系、高质量答案解析、理论与实践结合
6. 安全研究与分析
- 威胁情报自动化分析、漏洞模式挖掘、攻防技术知识库构建
- 支撑安全研究和创新应用
⚡ 8️⃣ 性能优化技巧与最佳实践
数据加载三大优化策略
对于2.2GB的大型数据集,建议采用以下优化策略:
- 分块加载 – 逐块处理数据,避免内存溢出
- 代码示例: chunk_size=10000
- HuggingFace Datasets – 启用流式模式,内存占用恒定
- 代码示例: streaming=True
- 数据预处理与缓存 – 预处理后缓存,后续直接加载
- 代码示例: 使用pickle缓存
训练优化建议
- 初期训练:使用全部数据进行泛化能力训练
- 微调阶段:根据任务需求采样特定领域数据
- 难例挖掘:重点关注模型预测错误的数据
- 数据增强:翻译增强、回译增强、同义词替换
📏 9️⃣ 如何评估数据集质量?
提供三个评估维度:
人工抽样检查
- 至少抽样100-500条数据,检查技术准确性、代码可执行性、答案完整性
- 覆盖不同领域和评分区间
- 重点关注边界情况
自动化评估
- 编写脚本自动检查字段完整性、内容长度、代码块、结构化内容、专业术语
- 字段完整性检查
- 内容长度验证
- 代码块检测
- 专业术语匹配
模型验证
- 使用训练好的模型在测试集上评估准确率、完整性、安全性、实用性
- 准确率:模型输出的正确性
- 安全性:是否输出危险操作建议
📊 🔟 与其他数据集的对比分析
| 特性 | 本数据集 | 通用安全数据集 | 学术数据集 |
| 数据量 | 27万+ | 数百万 | 数千-数万 |
| 质量 | ≥4.5分严格筛选 | 质量参差不齐 | 质量较高 |
| 更新频率 | 定期更新 | 不固定 | 一次性 |
| 应用场景 | 实战导向 | 研究导向 | 学术研究 |
| 语言 | 中英文 | 英文为主 | 英文 |
| 成本 | 开源免费 | 部分收费 | 免费 |
核心优势:
✅ 质量保证:经过严格清洗和评分
✅ 实战导向:包含大量实战案例和操作指南
✅ 双语支持:中英文混合,适合国内应用
✅ 开源免费:MIT许可证,可商用
✅ 持续更新:跟踪最新安全趋势
❓ 1️⃣1️⃣ 常见问题FAQ
Q1: 为什么选择JSONL格式而不是JSON或CSV?
JSONL格式支持流式处理、易于扩展、容错性强、灵活性好。对于2.2GB的数据集,JSONL格式大大降低了内存占用。
Q2: 如何确保数据不包含过时的漏洞信息?
数据清洗时会检查时效性,移除已过时的漏洞信息,更新为最新的修复方案。建议用户关注数据集的更新日期。
Q3: 可以用于商业吗?
可以。本数据集采用MIT许可证,允许商业使用。建议遵守开源协议、适当引用数据来源、注意数据安全。
Q4: 如何贡献数据或报告问题?
• 加入QQ交流群:253193620
• 访问官方博客:https://hcnote.cn
• 提交Issue或Pull Request到GitHub仓库
Q5: 数据集适合初学者吗?
本数据集覆盖从基础到的完整知识体系,适合不同水平的学习者:
• 初学者:从基础安全概念开始
• 进阶者:深入Web安全、渗透测试
• 专家:研究攻击技术、防御策略
🚀 1️⃣2️⃣ 未来发展方向与路线图
数据规模扩展
- • 持续收集高质量数据
- • 覆盖更多安全领域(云安全、物联网安全、区块链安全)
- • 增加多语言支持(日语、韩语、德语等)
质量进一步提升
- • 引入专家人工审核机制
- • 添加用户反馈和质量评分系统
- • 动态质量评分和持续优化
功能增强
- • 添加数据标签(分类、难度、主题等)
- • 提供RESTful API接口
- • 支持在线查询和测试平台
生态建设
- • 开发配套工具(数据可视化、质量分析)
- • 构建社区贡献平台
- • 与其他数据集的融合和互补
💡 1️⃣3️⃣ 总结与行动指南
高质量的训练数据是构建AI模型的基础。本文详细介绍了一个经过严格清洗和质量筛选的网络安全数据集,包括:
- • 数据结构:JSONL格式,包含instruction、output、id三个字段
- • 清洗流程:五步严格流程,质量评分≥4.5分
- • 覆盖领域:Web安全、威胁情报、系统安全、网络安全、基础概念
- • 应用场景:LLM微调、RAG系统、问答机器人、知识图谱、教育培训
- • 性能优化:分块加载、流式处理、数据缓存
🎯 行动指南:
1. 立即访问:https://modelscope.cn/datasets/hcnote/Cybersecurity-High-Quality-Dataset下载数据集
尝试应用:使用数据集训练你的第一个网络安全AI模型
🎉 如果这篇文章对你有帮助,欢迎收藏、分享,让更多人了解高质量网络安全数据集的价值!
________________________________________________________________________________
🏷️ SEO关键词
网络安全数据集、AI训练数据、大语言模型、LLM微调、数据清洗、DataSanity、Web安全、威胁情报、RAG系统、知识图谱、JSONL格式、高质量数据、网络安全、人工智能、机器学习
相关搜索词:
网络安全数据集下载、AI训练数据清洗、网络安全LLM、高质量数据集、网络安全知识图谱、RAG系统构建
📧 联系方式
作者:幻城
公司:新疆幻城网安科技有限责任公司
QQ交流群:253193620
官方博客:https://hcnote.cn
数据集下载:https://modelscope.cn/datasets/hcnote/Cybersecurity-Dataset
清洗工具:https://github.com/yangqi1309134997-coder/DataSanity
许可证:MIT License
发布日期:2026年1月
© 2026 新疆幻城网安科技有限责任公司 | 保留所有权利
暂无评论内容