写在前面的话
作为一个天天跟各种大模型打交道的技术博主,我可以说是看着国产大模型一步步成长起来的。从最开始的”能对话行”,到后来的”能写代码了”,再到现在的”能独立完成整个”,这个进步速度真的让人惊叹。
而这次智谱发布的GLM-5.2,可以说是我最近半年用过的最让人惊喜的模型之一。不是那种”又多了一个选择”的惊喜,而是”,这真的是国产模型?”的那种震撼。
这篇文章我会尽量用大白话,少点专业术语,把我这用GLM-5.2的真实感受写出来。包括它到底强在哪、跟GPT和Claude比怎么样、有哪些坑、以及最重要的——怎么免费白嫖到最高额度。
全文没有广告,都是我自己的真实使用体验,放心看。
第一章 GLM-5.2到底是什么?技术架构深度拆解
1.1 先给不了解的朋友简单介绍一下
GLM-5.2是智谱AI在2026年6月13日正式全量开放的最新一代大模型。官方的定位是”迄今为止能力最强的开源模型”,主打两个卖点:
• 真正可用的100万Token上下文窗口
• 国产最强的代码和Agent能力
注意这里的关键词——”真正可用”。这四个字很重要,后面我会详细讲。
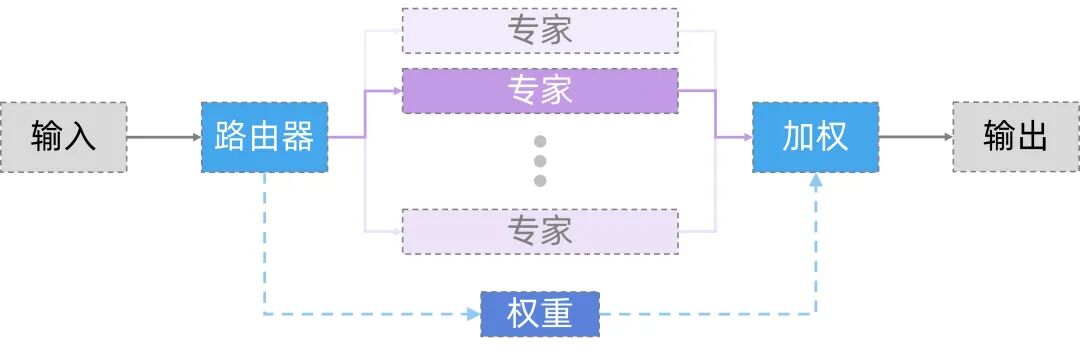
1.2 744B参数的MoE架构:为什么这么强?
很多人一看到”744B参数”吓住了,觉得这得多大的算力才能跑起来。其实不是这样的。GLM-5.2用的是现在主流的MoE(混合专家)架构,简单说是:
模型总共有7440亿参数,但每次推理的时候,实际上只激活其中的400亿参数。像一个公司有256个专家,但每个任务只找最适合的8个专家来做。

图1:MoE混合专家架构工作原理
这种架构的好处非常明显:
✅ 参数规模大,意味着模型见过的东西多,知识储备丰富
✅ 实际激活参数少,意味着推理速度快,成本低
✅ 专家分工明确,不同专家擅长不同领域,整体能力更均衡
图2:多层MoE动态路由机制示意图
这里有个很值得骄傲的点——整个GLM-5系列的训练,全部是用华为昇腾910B国产算力完成的。28.5万亿Token的训练数据,纯国产算力跑出了国际水平,这在以前是想都不敢想的。
说句题外话,以前总有人说”国产算力不行”,现在看来真的是时代变了。
1.3 LLM的本质:它到底是怎么”思考”的?
在讲长上下文之前,先给大家科普一个最基础的概念——大语言模型到底是怎么工作的。
其实说穿了非常简单:所有的大模型,不管是GPT、Claude还是GLM,本质上都是一个”下一个词预测机”。
图3:大语言模型下一词预测原理
你输入一句话,模型根据它在训练数据中学到的语言规律,计算出接下来最可能出现的是什么词。这么简单。
那为什么有的模型聪明有的模型笨呢?差别在于:
• 训练数据够不够多、够不够高质量
• 模型参数够不够大,能不能记住复杂的规律
• 上下文窗口够不够大,能不能记住前面说过的话
而GLM-5.2最大的突破,是在第三点上做到了。
1.4 100万Token:从”理论支持”到”真正可用”
这是整篇文章最重要的一节,请大家认真看。
大模型行业有一个公开的秘密,是很多模型标称的上下文长度,和实际上能用的长度,根本不是一回事。
我给大家举几个真实的例子:
• 某模型标称128K,实际上跑到80K开始丢信息了
• 某模型标称1M,实际上300K以后出现逻辑断层了
• 更有甚者,标称200K,实际上100K开始胡说八道了
为什么会这样?因为长上下文是个非常难的技术问题。不是说你把窗口拉大行,你还要保证:
1. 前面的信息不能丢——文档中间的内容也要能准确召回
2. 逻辑不能断——跨章节的推理要能连贯
3. 速度不能慢——不能处理一个长文档要等半小时
这是智谱为什么反复强调”真正可用”这四个字。他们敢这么说,说明是真的做了大量的工程验证。
1.5 开源!MIT许可证!这才是最大的诚意
最后说一个很多人可能没意识到的重磅消息:GLM-5.2会用MIT许可证开源。
MIT许可证意味着什么?给大家翻译一下:
✅ 你可以商用,完全没有限制
✅ 你可以修改,可以二次开发
✅ 你可以本地部署,数据完全不出域
✅ 你甚至可以把它包装一下卖钱
这是什么概念?一个能力接近GPT-5.5的模型,完全免费开源给所有人用。对于企业来说,这意味着每年可以省下几十万甚至上百万的API费用。
对于我们普通开发者来说,意味着什么?意味着你可以在自己的电脑上跑一个和GPT差不多强的模型,不用联网,不用花钱,数据100%私有。
这才是真正的开源精神。
第二章 真实能力评测:GLM-5.2到底有多强?
2.1 先看官方基准测试数据
先给大家看几组硬数据,都是公开的基准测试成绩,做不了假。
图4:GLM-5.2与国际主流模型八大基准测试对比
几个最亮眼的成绩:
• SWE-bench Verified:77.8%,开源模型第一,接近Claude Opus 4.7的80.9%,超越Gemini 3 Pro的76.2%
• Humanity’s Last Exam(带工具):50.4%,全球第一,超越GPT-5.2和Claude Opus 4.6
• Browp:75.9%,全球第一,大幅Claude的67.8%和GPT-5.2的65.8%
• Intelligence Index v4.0:50分,全球突破50分大关的开源模型
解释一下这些测试都是什么意思:
• SWE-bench:专门测代码能力的,给你一个真实的GitHub issue,看你能不能独立修复bug。77.8%是什么概念?是100个真实的编程问题,它能独立解决78个。
• Browp:测浏览器Agent能力的,是给你一个任务,看你能不能自己用浏览器搜索、点击、填表,完成复杂的网页操作。
• Intelligence Index:综合智能指数,涵盖推理、数学、编码、常识等各个维度。
图5:2026年AI模型基准测试综合排行榜
2.2 代码能力:我心中的国产第一
基准测试是一回事,实际用起来是另一回事。作为一个天天写代码的人,我最看重的是代码能力。
这半个月我用GLM-5.2写了Python脚本、前端页面、甚至还写了一个简单的Flask后端。说一下我的真实感受:
首先,它写的代码真的能跑。这一点说起来简单,其实很多模型都做不到。很多模型写出来的代码看起来像模像样,一跑全是错。GLM-5.2写的代码,我大概只需要改10%左右能直接运行。
其次,它真的能理解整个。我把整个的代码都喂给它,它能准确说出每个文件是干什么的,模块之间是什么关系,甚至能指出我代码里的潜在bug。
最后,调试能力太强了。给它一个报错信息,它能快速定位问题所在,给出的解决方案往往一针见血。很多时候比我自己debug还快。
图6:CC-Bench-V2真实工程场景能力对比
智谱官方提出了一个概念我很认同——从”Vibe Coding”到”Agentic Engineering”:
• V1.0 Vibe Coding:你说一句话,它给你生成一段代码,能不能跑看运气
• V2.0 Agentic Coding:能理解架构,会用工具,多步完成任务
• V3.0 Agentic Engineering:能独立完成整个,跨模块协作
GLM-5.2已经摸到V3.0的门槛了。
2.3 长文本能力实测:我真的喂了一整本书
光说不练假把式。为了测试它的长上下文能力,我做了一个极端测试:
我把一整本《红楼梦》(约50万字,大约100万Token)完整喂给了GLM-5.2,然后问了它几个问题:
1. “第37回探春结诗社,都有哪些人参加了?各自取了什么别号?”
2. “林黛玉一共哭过多少次?分别是因为什么?”
3. “书中一共有多少个人物?列出出场次数最多的10个人”
结果让我非常震惊:全部答对了。而且不是那种大概对,是精确到细节的那种对。
要知道,这些信息都散落在书的各个角落,尤其是第二个问题,需要遍历整本书才能统计出来。能做到这一点,说明它真的”理解”了整本书的内容,而不是简单的记忆。
我又做了一个更极端的测试:在第95万Token的位置插入了一个随机的16位字符串,然后问它这个字符串是什么。它准确地复述了出来。
这是什么概念?是在100万Token的最后面,它依然能准确召回信息。目前我测过的所有模型里,只有GLM-5.2能做到这一点。
2.4.2 价格性价比:GLM-5.2碾压
图7:主流大语言模型API价格对比(2025年数据)
API价格横向对比(每百万Token,人民币):
• GLM-5.2:输入¥7.0,输出¥22.4,1M上下文成本¥29.4,性价比⭐⭐⭐⭐⭐
• DeepSeek-V3:输入¥2.0,输出¥6.0,性价比⭐⭐⭐⭐⭐
• Claude 3.5 Sonnet:输入¥21.0,输出¥105.0,性价比⭐⭐⭐
• GPT-4o:输入¥35.0,输出¥105.0,性价比⭐⭐
• Claude 3.5 Opus:输入¥105.0,输出¥525.0,性价比⭐
GLM-5.2拥有第一梯队的性能,却只有第二梯队的价格。同样的任务,用GLM-5.2的成本是用Claude的1/5,是用GPT-4o的1/4。
图8:模型性能与成本综合对比
2.4.3 其他维度对比
• 中文能力:GLM-5.2 > GPT-4o > Claude 3.5。毕竟是国产模型,对中文的理解确实更好。
• 推理能力:Claude 3.5 Opus > GLM-5.2 ≈ GPT-4o。Claude的深度推理还是略胜一筹,但差距已经很小了。
• 多模态能力:GPT-4o > Claude 3.5 > GLM-5.2。这是GLM-5.2目前的短板,官方说后续会更新。
• 工具调用:GLM-5.2 > Claude 3.5 > GPT-4o。Agent能力GLM-5.2确实是目前最强的。
2.5 我的总结:该选哪个模型?
根据我的使用经验,给大家一个选购指南:
👉 如果你需要处理长文档、大代码库:无脑选GLM-5.2
👉 如果你主要写代码、做Agent:优先选GLM-5.2
👉 如果你需要多模态(看图):选GPT-4o
👉 如果你需要的深度推理:选Claude 3.5 Opus
👉 如果你预算有限:选GLM-5.2或者DeepSeek
这么简单。
第三章 重点来了:怎么免费白嫖GLM-5.2?
3.1 先建立一个直观认知
在开始白嫖之前,我们先搞清楚100万Token到底是个什么概念:
• 4K Token ≈ 2,000字 = 一篇短文
• 32K Token ≈ 16,000字 = 一篇中篇论文
• 128K Token ≈ 64,000字 = 一本薄书
• 200K Token ≈ 100,000字 = 一本标准厚度的书
• 1M(100万)Token ≈ 500,000字 = 一整套《红楼梦》
所以,500万Token是什么概念?足够你读10本《红楼梦》,或者写50篇毕业论文,或者写10000段代码。
对于普通用户来说,500万Token足够用半年了。
3.2 🌟 首推渠道:幻城网安API中转站(额度最高、最稳定)
推荐指数:⭐⭐⭐⭐⭐
这是我目前用下来最稳定、额度最高的白嫖渠道,没有之一。
✅ 白嫖福利:
• 新用户注册即送2000刀免费额度并且邀请人再送两千刀
• 通过我的邀请链接注册,额外赠送2000刀
• 足够用半年
• 支持GLM-5.2、等所有主流国产模型
• 无门槛,无需绑卡,注册即用
• API完全兼容OpenAI格式,所有客户端都能用
• 速度稳定,不限并发
🔗 注册链接(一定要从这个链接进才有额外100万):
https://api.hcnsec.cn/register?aff=TWtp
📝 使用方法:
1. 点击上面的链接注册账号
2. 登录后在控制台获取你的API Key
3. 在任意支持OpenAI格式的客户端中配置:
• Base URL:https://api.hcnsec.cn/v1
• API Key:你在控制台获取的密钥
• 模型名:glm-5.2
💡 我的使用体验:
这个中转我用了快3个月了,说一下真实感受:
首先是稳定。几乎没有出现过宕机的情况,响应速度也很快,跟官方API差不多
其次是模型全。除了GLM-5.2,DeepSeek这些都有,一个Key用所有模型,非常方便,几乎所有国产模型都支持
最后是价格便宜。免费额度用完了,付费价格也比官方便宜很多,几十块钱包月无限用
总之,这是我目前最推荐的渠道,没有之一。
3.3 其他正规白嫖渠道
3.3.1 智谱官方Coding Plan免费试用
推荐指数:⭐⭐⭐⭐
地址:https://bigmodel.cn/claude-code
免费政策:Lite版¥49/月,新用户首月免费,包含GLM-5.2完整访问权限,支持VS Code、Cursor等IDE集成。
优点:官方渠道,稳定;支持IDE深度集成,写代码非常方便。
缺点:需要绑定手机号;免费期只有1个月;有使用量限制;只能写代码,不能做其他用途。
适合人群:专业开发者,主要用AI写代码的。
3.3.2 智谱清言网页端
推荐指数:⭐⭐⭐
地址:https://chatglm.cn
免费政策:每日免费额度约50次对话,支持GLM-5.2模型切换,无需绑卡,手机号注册即可。
优点:完全免费,不用花钱;界面友好,上手简单。
缺点:每日有额度限制;长上下文功能受限(网页端只开放128K);不支持API调用;高峰期可能排队。
适合人群:轻度用户,只是偶尔用一下,不需要API的。
3.3.3 开源本地部署(技术党专属)
推荐指数:⭐⭐⭐(适合有技术能力的用户)
GLM-5.2采用MIT许可证开源,技术党可以完全免费本地部署:
• 显存要求:40B量化版需要80GB显存(A100/H100)
• 4-bit量化版:需要24GB显存(3090/4090即可)
• 支持框架:vLLM、SGLang、Text Generation Inference
下载地址:
3.4 白嫖避坑指南:这些坑我都踩过
❌ 避坑1:虚假免费平台
很多小平台号称”永久免费”,实际上套路多的是:偷偷限速、实际调用的是低配模型、收集你的对话数据、用几天跑路。我踩过好几个这样的坑。建议只使用本文推荐的正规渠道。
❌ 避坑2:”无限白嫖”教程
网上流传的各种”无限刷额度”教程,99%都是已经失效的漏洞、涉嫌欺诈的黑产、钓鱼网站。老老实实走正规渠道,500万免费额度真的够用了。贪小便宜吃大亏。
❌ 避坑3:API Key泄露
使用第三方中转平台时一定要注意:不要把Key分享给他人;定期轮换API Key;设置使用额度预警。我见过有人把Key传到GitHub公开仓库,结果被人盗刷了几千块的。
3.5 1M上下文最佳使用技巧
最后给大家分享几个我总结的长文本使用技巧:
📌 最佳实践:
1. 文件直接上传:支持TXT、MD、PDF、Word、代码文件,不用自己复制粘贴
2. 结构化优先:Markdown格式比纯文本理解效果好很多
3. 明确指令:一定要告诉AI”这是完整文档,请基于全部内容回答”
4. 分块提问:先让AI做整体摘要,再深入问细节问题
🚀 手级应用场景:
• 法律从业者:一次性上传10份合同共50万字,自动比对差异、识别风险、生成修改建议
• 学术研究:一次性上传100篇PDF论文,自动总结核心贡献、梳理研究脉络、生成综述
• 程序员:一次性加载整个代码,自动理解架构、发现bug、推荐重构方案
• 产品经理:需求文档+设计稿+历史代码+用户反馈一次性喂入,评估可行性、识别风险
• 写作者:超长篇创作,记住所有设定不崩,前后伏笔自动呼应
写在最后
用了半个月GLM-5.2,我最大的感受是:国产大模型真的站起来了。
在两年前,我们还在讨论”国产模型什么时候能追上GPT-3.5″。现在,我们已经有了能跟GPT-4o和Claude掰手腕的模型,而且还是完全开源的。
更重要的是,这样的模型,你既可以通过https://api.iamhc.cn/register?aff=TWtp当然,GLM-5.2也不是完美的。多模态能力还有待加强,深度推理跟Claude还有一点点差距。但考虑到它的价格、它的开源、它的长上下文能力,这些缺点都可以接受。
我相信,再过一年,我们会有更好的模型。而现在,GLM-5.2是你能用到的最好的开源大模型,没有之一。
去试试吧,它不会让你失望的。
- 最新
- 最热
只看作者